Did you know there are over 200 blogs in this MOOC? At least according to the blog directory there are about 220, but there could be more that are private.
Anyway, I found it challenging to peruse posts via the activity page and blog directory, and I found that there were too few when limited to my homeroom feed that Henry, @henare had set up. Although I could have subscribed to all the homeroom feeds that Henry created in Yahoo Pipes, I rather like to see which particular blog a post is from rather than which homeroom it is from. So I set a challenge for myself. Create an OPML file! But 220 is way too tedious to do one by one. I know, I did 40 of them and gave up.
I looked at the Pipes, but couldn’t see how I could extract the list of RSS feeds individually, so what next?
It worked for me. :)

Anyone else want it? The opml file is available.
This may have taken just as long as continuing with the manual method, but this was far less boring as I was learning new stuff as I went - including some handy new tricks with Notepad++ regular expression. And I decided to write this post as I went so that made it take longer too.
Anyway, I found it challenging to peruse posts via the activity page and blog directory, and I found that there were too few when limited to my homeroom feed that Henry, @henare had set up. Although I could have subscribed to all the homeroom feeds that Henry created in Yahoo Pipes, I rather like to see which particular blog a post is from rather than which homeroom it is from. So I set a challenge for myself. Create an OPML file! But 220 is way too tedious to do one by one. I know, I did 40 of them and gave up.
I looked at the Pipes, but couldn’t see how I could extract the list of RSS feeds individually, so what next?
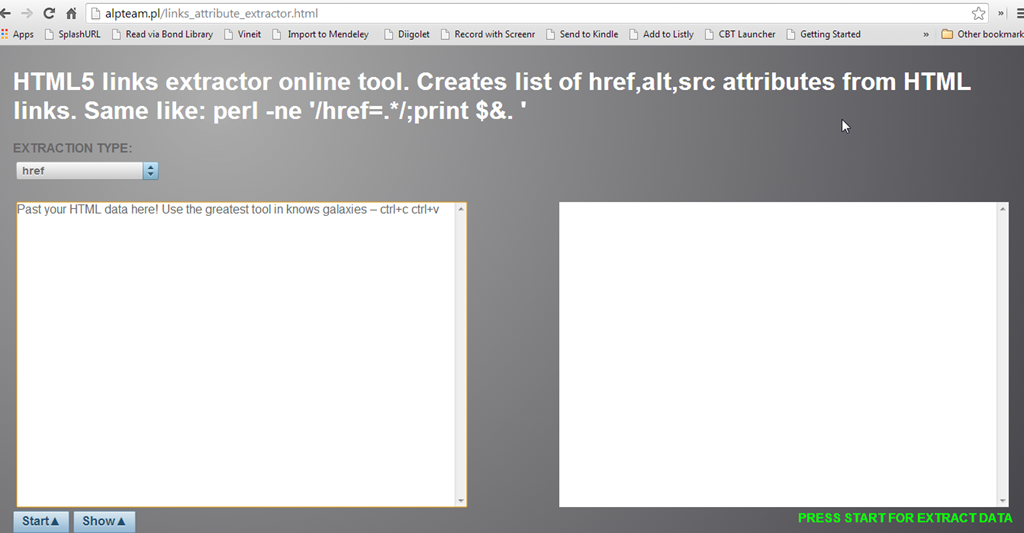
- Install extension in Chrome – “Link Extraction” – and open in a new tab
- Navigate to the blog directory in a new tab, and sort alphabetically (not essential, but just in case recent activity caused the list to change before I finished and I missed a blog or two)
- Highlight the list of blogs – at first I just copied the whole page, but that meant I had more unwanted links to clean out later – and Control-C
- Back to the Link Extraction tab
Control-V into the left-hand box - Click the Start button
- Copy the list of links from the right-hand box
- Paste into Notepad++
- Repeat for each page of the blog directory
- Save the file
- In Notepad++ use the Find and Replace function to replace the spaces with a new line using the regular expression option /n – This will put each link on a new line
- Install the TextFX plugin for Notepad++ using the Plugin Manager built into Notepad++
- Tick the +Sort ascending and +Sort outputs only UNIQUE (at column) lines
- Control-A to select the entire file, then in the TextFX menu choose Sort lines case sensitive (at column) – This will sort all the links alphabetically and remove duplicates.
- Scan through the list and remove lines that are clearly not blogs – these were mostly links to other parts of the MOOC such as /badges. However if I had followed step 3 closely from the beginning there would have been fewer of these to weed out.
- Scan through and remove any lines that contain wp-admin – I was aiming for just a list of links to the home page of each blog, but I still had links to the latest post from each blog to weed out.
- Use Find and Replace function to replace “?p=” with a new line using the regular expression option
- Repeat step 14
- Highlight all the rows that are just numbers (the page number) and delete them – this resulted in a list that looked very close to what I wanted.
- Using the Find and Replace function append “feed/” to the end of each row assuming that every blog has the same syntax in the feed URL


- Copy the entire file and paste into FeedShow OPML builder using the List of Links text box – then click the generate OPML button
- Copy the generated code and paste into a fresh Notepad++ file
- Change the first outline row to reflect the name of the set of feeds.
- Use Find and Replace function to trim the ‘title’ attribute down to just the name of the blog (well at least the bit you can get between edu/ and /feed
- Save as file type xml
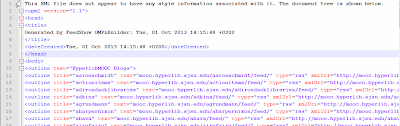




It worked for me. :)

Anyone else want it? The opml file is available.
This may have taken just as long as continuing with the manual method, but this was far less boring as I was learning new stuff as I went - including some handy new tricks with Notepad++ regular expression. And I decided to write this post as I went so that made it take longer too.